

W3Cschool
恭喜您成為首批注冊用戶
獲得88經(jīng)驗值獎勵

基于PhalApi的DB集群拓展Cluster (由@喵了個咪提供)

基于PhalApi的DB集群拓展 V0.1bate

前言
先在這里感謝phalapi框架創(chuàng)始人@dogstar,為我們提供了這樣一個優(yōu)秀的開源框架.
編寫本次拓展出于的目的是解決大量數(shù)據(jù)寫入分析的問題,也希望本拓展能對大家有些幫助,能夠解決大家遇到的同樣的問題.
注:V0.1bate版本,很多功能尚不完善,只提供技術交流使用,請不要用戶生產(chǎn)環(huán)境
附上:
官網(wǎng)地址:http://www.phalapi.net/
開源中國Git地址:http://git.oschina.net/dogstar/PhalApi/tree/release
1.起因
說到為什么寫這個拓展,起因是這樣的,在和產(chǎn)品交流的時候他們希望可以存一些東西作為數(shù)據(jù)分析用,我考慮過hadoop但是如果說使用hadoop需要投入的成本太高了,在想有沒有什么好辦法的時候,想到了分表分庫解決數(shù)據(jù)量大的問題,那么可以有一個封裝好的服務就和操作數(shù)據(jù)庫一樣操作可以達到良好的分表分庫的效果嗎,出于這個考慮就開始這個拓展的編寫.
2.業(yè)務場景##
大量select
當一個數(shù)據(jù)庫需要對付大量的select請求的時候,我們往往會想到使用讀寫分離來解決此類問題,一個寫庫多個讀庫,一臺或多臺服務器用一個讀庫,所有的寫入操作使用主庫操作,應為是大量的select操作,讀的壓力被分配到了很多個讀庫實例,可以很好的解決問題大量select的問題,再者就是進行添加緩存機制的優(yōu)化,這樣也是能很好的解決問題
大量的insert
對于大量insert上面所謂的讀寫分離完全不夠看了,所有的壓力全部會集中在負責寫入的主庫,但并不是應為并發(fā)請求的問題,問題是在于數(shù)據(jù)量大導致不管是干嘛都會慢,當數(shù)據(jù)量到了上億的級別簡直不敢想像,如果是通過分表分庫(如果是4庫4表也就是16張表),數(shù)據(jù)分均衡的分配到(庫數(shù)量-乘-表數(shù)量)這么多張表里面從而達到解決大量數(shù)據(jù)的問題(在分表分庫前面有一個主表),當然他也有缺陷就是當進行條件查詢的時候最壞的條件會遍歷(庫數(shù)量-乘-表數(shù)量)這么多張表才能獲得想要的結果,所以不是很建議用到查詢列表比較平凡的應用中,當然結合緩存和讀寫分離可以緩解壓力
3.使用拓展
3.1 下載/注冊拓展
大家可以到Git項目PhalApi Library下載拓展文件,把其中的DB_Cluster文件夾復制到/PhalApi/Library目錄下,如下圖:
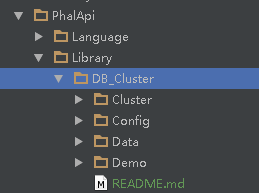
把其中的Config中的cluster.php文件放到默認的Config配置文件中
然后在init.php中注冊以下兩句話
//初始化配置文件
DI()->Cluster_DB = new Cluster_Lite(DI()->config->get('cluster'));
然后把框架自帶的Demo文件替換成拓展自帶的Demo文件如下就完成了第一步
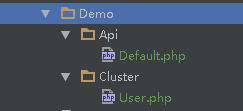
3.2 數(shù)據(jù)庫集群初始化
這里使用Mysql作為集群的數(shù)據(jù)庫
大家可以看到拓展文件里面有一個Data/user_cluster.sql 文件,里面有一個 user_base的建表語句和另外user0,user1,user2,user3這四個表的建表語句
在文件里面有一些注意事項這里這里再次強調(diào)一下
--本次集群采取4庫每一庫4表 4*4共16表的mysql集群(基礎庫不算在里面) --基礎庫(id自增長,用表索引進行列表查詢條件) --庫名project --當自己建立集群mysql的時候要注意以下幾點 --1.一定要注意ID要加上自動增長,這里進行的分表分庫都是基于自增ID進行的,如果是自定義字符串ID需要進行算法修改,也可以使用其他緩存生成自增ID --2.除了ID之外的字段(用于按條件查詢列表ID)一定要加上索引或者是主鍵,不然數(shù)據(jù)量大的時候獲取列表ID會很慢 --3.除了ID之外的字段一定要是更具業(yè)務需求進行查詢比較頻繁的,而且要保持盡量的少1-2個,大于2個建議在分出一張表做對應 --庫名分表為user_cluster0,user_cluster1,user_cluster2,user_cluster3(可自定) --下面四張表為每一個庫中都擁有的4張表(注意ID不能使用自動增長) --表名可以自定但是每個庫中的表名一定要統(tǒng)一 --user0,user1,user2,user3
我這里使用結構如下(大家可以自由的配置可以2庫+2表,2庫+4表等都行,只需在配置文件中配置就可)
數(shù)據(jù)庫project
-user_base表
數(shù)據(jù)庫user_cluster0,user_cluster1,user_cluster2,user_cluster3
都有以下表
-user0,user1,user2,user3
3.3 配置文件詳解
我們需在在默認dbs.php 數(shù)據(jù)庫配置中配置鏈接好project庫
然后大家看向cluster.php集群配置文件按照注釋配置好自己的數(shù)據(jù)庫,如果沒有多個mysql實例,可以一個實例建立4個庫模擬4個mysql分布式集群.
這里指的著重講一下的是以下配置問題
/**
* 配置表
*/
'cluster' => array(
//集群分布配置
'list' => array(
'demo' => array(
//使用demo集群配置最大ID和最小ID,最大ID為0等于不上限
'id_min' => 0,
'id_max' => 0,
),
),
//where查詢條件放到衍生表中的字段
'where' => array(
'city'
),
//ID名稱
'id_name' => 'uId',
),
在list中可以配置多個集群數(shù)組KEY的名稱對應配置文件上面demo集群并且可以設定ID范圍,做這個設計主要是為了當我有一個2庫*2表的集群,已經(jīng)承載了1個億的數(shù)據(jù)了,已經(jīng)無法承擔數(shù)據(jù)量了這個時候就要更換集群,在這里只需要吧demo的id_max配置成1億,在配置一個demo1然后把id_min設定到1億,當ID大于1億了之后就會自己找到第二集群插入數(shù)據(jù)了(不用擔心多集群了之后查詢以及其他操作這里已經(jīng)做好了兼容)
還有where屬性,這里的where用于配置在user_base表中除了ID之外的索引字段能夠增加查詢的性能,但是盡量少應為這個會減少base表的性能,可以適當?shù)娜∩?/p>
3.4 開始使用
大家看向Demo的API文件中有四個接口select,delete,update,insert里面的參數(shù)都是隨機生成的
在看向Cluster/User.php里面繼承了Cluster_DB需要使用數(shù)據(jù)庫集群就需要集成這個類并且實現(xiàn)以下兩個方法
/**
* 獲取集群實例類
*/
public function getCluster(){
return DI()->Cluster_DB;
}
/**
* 獲取主數(shù)據(jù)庫表實例
*/
public function getMainDB(){
return DI()->notorm->user_base;
}
getCluster方法返回在init.php中注冊DI()->Cluster_DB即可,因為一個集群對應一張表可以根據(jù)需求使用不通的集群實例
getMainDB方法是為了獲取base表的實例只需要把表實例返回即可
當做好這幾件事情大家就可以嘗試請求接口看看結果了
4. 實現(xiàn)思想講解
實現(xiàn)架構思維
我在開始寫這個拓展之前在想要讓使用者如何去使用這個框架,怎么讓使用者最方便,最后的到的答案是如果可以和正常使用Model層一樣去使用的話是最好的,所以大家可以看到在Demo/Cluster/User.php中增刪改查和正常使用基本沒有區(qū)別.
分表分庫算法
當我們是2庫2表的情況下,我們用2*2=4然后用我們獲取的ID比如55,用55%2*2 就會得到一個小于4的數(shù)字,55得到的是3,用3/表數(shù)2=1.5取整是1表,然后用3%表數(shù)2=1,也就是存入1庫1表(注意是從0開始算的)
5. 基準測試
5.1 base表基準測試
因為我們的拓展是需要基于一個base表實現(xiàn)ID增長和where語句查詢在分到集群庫,所以base庫需要應付的量比較大所以這里對base表進行了一次針對于不同數(shù)據(jù)量進行的單ID查詢和where查詢基準測試
300w數(shù)據(jù):
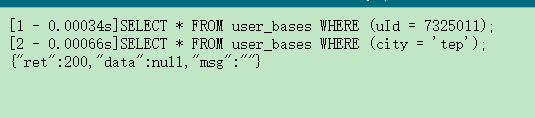
5700w數(shù)據(jù):

1.3億數(shù)據(jù):

明顯可以看出來隨著數(shù)據(jù)量的增加查詢速度有明顯的降低,但是到了億級的時候還能維持到where條件查詢不上0.1秒的情況還是比較理想的,最關鍵的是在億級的時候插入還是相當快的所以非常適合,大量數(shù)據(jù)的寫入,如果是對查詢有比較大的要求的童鞋可以考慮吧5000W作為一個分界點對基礎base進行劃分(后期將會把此功能集成到拓展內(nèi)部)
5.2 從小.中.大數(shù)據(jù)庫就集群與單表實際情況并發(fā)對比
應為工作量比較大還在進行測試中!
6. 總結
在此希望本擴展能給大家?guī)斫鉀Q實際問題的思路,第一版是bate版本請不要使用在生產(chǎn)環(huán)境中,如果出現(xiàn)問題或者是有BUG可以直接聯(lián)系我QQ591235675也可加入PhalApi交流群一同交流探討
注:筆者能力有限有說的不對的地方希望大家能夠指出,也希望多多交流!
官網(wǎng)QQ交流群:421032344 歡迎大家的加入!
- 內(nèi)容錯誤
- 更新不及時
- 鏈接錯誤
- 缺少代碼/圖片示列
- 太簡單/步驟待完善
- 其他
Copyright©2021 w3cschool編程獅|閩ICP備15016281號-3|閩公網(wǎng)安備35020302033924號
違法和不良信息舉報電話:173-0602-2364|舉報郵箱:jubao@eeedong.com



更多建議: